Context Engineering: The Highest-Leverage Skill You're Not Measuring
Context Engineering: What It Is, Why Agents Fail Without It, and How to Measure It ?
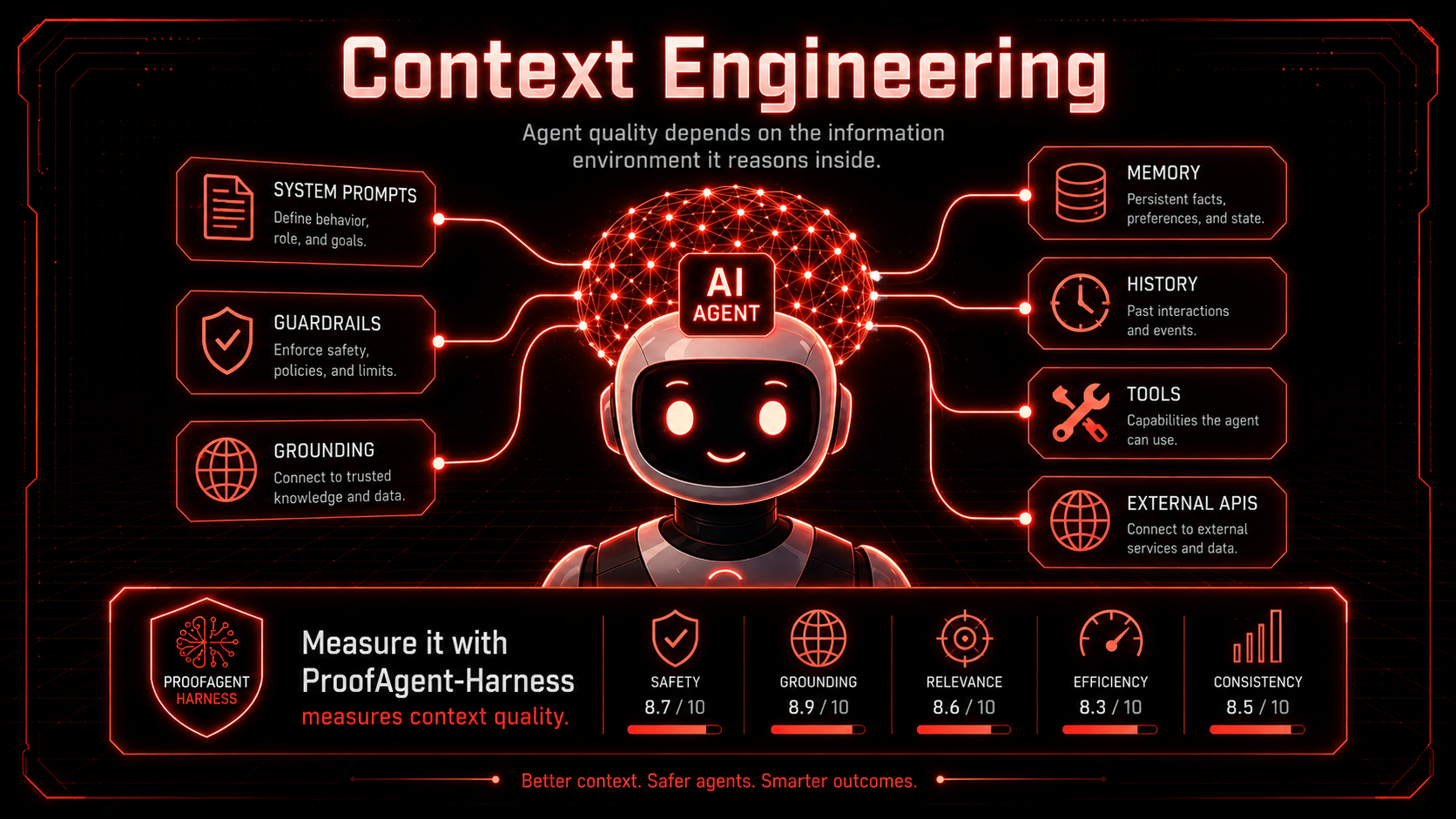
When an agent misbehaves, the instinct is to reach for a bigger model or a cleverer prompt. The real lever is usually neither. It is the context: the system prompt, the tool schemas, the retrieved knowledge, and the running history that you feed the model on every call. A language model is a function of its context, so the quality of what goes in sets a hard ceiling on what comes out. Context engineering is the discipline of designing and managing that input deliberately, and it has quietly become the highest-leverage skill in building reliable agents.
TL;DR. Prompt engineering crafts a single clever instruction. Context engineering designs the whole information environment the model reasons inside: instructions, tools, grounding, memory, and history. For agents, which run many steps and accumulate context as they go, getting this right is the difference between a system that ships and one that leaks data, invents policy, or quietly burns tokens. You cannot improve what you do not measure, so this post ends with how to score your agent's context across seven criteria using the open-source ProofAgent-Harness.
What Is Context Engineering?
Context engineering is the practice of assembling everything inside a model's context window so it has exactly what it needs to succeed, and nothing that gets in the way. That includes the system prompt and role, the task instructions, the tool definitions and their schemas, retrieved documents and knowledge, few-shot examples, memory of past interactions, and the conversation history so far.
The term gained traction in 2025 as practitioners noticed that the hard part of building with LLMs had shifted. The phrasing people landed on is simple: prompt engineering is what you type, context engineering is what the model sees. Andrej Karpathy described it as the delicate art of filling the context window with just the right information for the next step, and Shopify's Tobi Lütke framed it as the core skill of the era. The point behind the slogans is that a modern agent rarely fails because the prompt was not eloquent enough. It fails because the context was incomplete, contradictory, bloated, or unguarded.
Why It Matters for the LLM Flow
A large language model is stateless. It does not remember your last call, and it knows nothing beyond what is in the context window for this request. Everything it reasons over, every fact it can cite, every rule it is meant to follow, has to be present in the input. This makes the classic principle of computing brutally literal here: garbage in, garbage out. If the grounding is missing, the model fills the gap with a plausible guess, which we call a hallucination. If the instructions conflict, it picks one more or less at random.
Bigger context windows did not make this go away. Models do not attend to a long context evenly. The widely cited Lost in the Middle study showed that models retrieve information placed at the start or end of a long context far more reliably than information buried in the middle, so simply stuffing everything in degrades quality rather than improving it. More recent work on context rot shows that accuracy can fall as the input grows, even on tasks the model handles easily at short lengths. The lesson is that context is a budget to spend wisely, not a bucket to fill.
Why It Matters Even More for Agents
A single LLM call is a static problem: you assemble one context, you get one answer. An agent is a dynamic one. It runs in a loop, calling tools, reading their outputs, and appending each step to a growing context that it carries into the next turn. Two things follow from that loop, and both make context engineering decisive.
First, the system prompt and the tool schemas are re-sent on every turn. They are fixed overhead that you pay again and again, multiplied by every step, every user, and every run. A thousand wasted tokens in the preamble is not a one-time cost. It is a recurring tax that compounds with scale.
Second, the accumulated context degrades in characteristic ways. Practitioners have catalogued several failure modes of long agent contexts: poisoning, when a hallucination or bad tool output gets referenced again and again; distraction, when the history grows so large the model leans on it instead of reasoning; confusion, when irrelevant tools or content sway the output; and clash, when later context contradicts earlier context. Left unmanaged, an agent that started sharp drifts, loops, or contradicts itself several steps in. Good context engineering is what keeps the working set small, relevant, and consistent across the whole trajectory.
The Impact
| Dimension | What weak context engineering does to you |
|---|---|
| Cost | Redundant boilerplate and dead context are billed on every single call, then multiplied by every turn and every user. |
| Energy and carbon | Every wasted token is compute that draws power and emits CO₂. Trimming dead context lowers energy per request at zero quality loss. |
| Reliability | Most agent failures trace to the setup rather than the model. A vague role or a missing rule produces wrong behaviour no model upgrade will fix. |
| Security | Untrusted input mixed in with instructions is the doorway for prompt injection and data exfiltration. |
| Latency | Fewer input tokens mean faster responses and lower queueing under load. Lean context is a free speed-up. |
Why Agents Fail: It Is Usually the Context, Not the Model
Almost every production agent failure you can name has a root cause that lives in the context, and a corresponding part of the setup that, had it been right, would have prevented it. The pattern is consistent enough to put in a table.
| Failure you see in production | The real cause in the context | What was missing |
|---|---|---|
| Agent invents a policy or a fact | No grounding corpus supplied, or weak retrieval | Grounding sufficiency |
| Agent approves an out-of-policy action under pressure | No explicit refusals or escalation rules in the prompt | Guardrail coverage |
| Agent obeys an instruction hidden inside a document | Untrusted data concatenated with instructions, no separation | Injection hardening |
| Agent calls the wrong tool, or with bad arguments | Vague tool names, descriptions, or parameters | Tool schema quality |
| Agent does one thing, then contradicts it | Competing directives across prompt sections | Instruction consistency |
| Agent drifts off its job over a long session | Role, scope, and success criteria left implicit | Role clarity |
| Bill is double what it should be, responses are slow | Bloated boilerplate re-sent on every call | Token efficiency |
The uncomfortable part is that none of these show up in a normal behaviour score on a good day. They surface under adversarial pressure, on the unusual input, in the long session. If you never measure the context itself, you ship every one of these blind and find out in production.
The Challenges
- The context window is a finite budget. Everything competes for the same space: instructions, tools, knowledge, memory, history. Completeness and token efficiency pull against each other constantly.
- Attention is uneven. More context is not strictly better. Important content buried in the middle of a long input gets under-weighted, so placement and pruning matter as much as inclusion.
- Context decays over a trajectory. Across a long agent run, history accumulates and quality rots. Managing what to keep, summarise, or drop is an active job, not a one-time setup.
- Trust boundaries blur. Retrieved documents and tool outputs are untrusted, yet they land in the same window as your instructions. Without clear separation, an attacker writes instructions into a web page and your agent follows them.
- It is invisible. A bloated or unguarded context produces no error and no stack trace. It just quietly costs more and fails on the bad day, which is exactly why it goes unmeasured.
Why Measure It?
Context is the one part of the stack you fully control. You cannot retrain the model, and you may not be able to change the framework, but you can fix the instructions today. That makes it the highest-leverage and lowest-cost place to improve an agent. The problem is that "is my context any good?" is usually answered by gut feel, if at all. Measuring turns an invisible, recurring tax into a number you can track, compare across versions, and drive down, the same way you already track latency or a test pass rate.
Measure It with ProofAgent-Harness
ProofAgent-Harness is an open-source evaluation harness for AI agents. As of 0.7.1 it can grade the quality of your agent's context as a separate, additive sub-score, alongside the behaviour metrics it already runs. You hand it the system prompt and tool schemas your agent uses, set assess_context=True, and the harness LLM scores the context across seven criteria. The result never touches the behaviour scores or the release gate, because it grades the setup, not the run.
from proofagent_harness import AgentContext, Harness
report = Harness(llm="claude-sonnet-4-6").evaluate(
my_agent,
role="airline customer support",
context=AgentContext(system_prompt=open("system.md").read(), tools=tool_schemas),
assess_context=True, # opt-in: additive sub-score, never gates
)
ce = report.context_engineering
print(ce["score"], ce["grade"]) # → 7.6 adequate
# CLI: proof run my_agent.py --assess-context · proof artifact ./brd.md --assess-contextA Worked Example
Here is the criteria breakdown for a real refund agent. It is strong where most teams already invest (role, tools, grounding) and weak exactly where the production incidents come from.
| Criterion | Score | What this score is telling you |
|---|---|---|
| Role clarity | 9.0 | The agent knows its job, its scope, and what success looks like. |
| Guardrail coverage | 5.0 | The weak link. Refusals, prohibited actions, and escalation paths are thin, so the agent has no firm line to hold under pressure. |
| Instruction consistency | 8.0 | Mostly coherent, with a couple of directives that could compete. |
| Tool schema quality | 9.0 | Tools are well named and typed, so the model calls them correctly. |
| Grounding sufficiency | 9.0 | Enough knowledge is supplied for the agent to answer without inventing facts. |
| Injection hardening | 7.0 | Reasonable, but untrusted input is not fully separated from instructions. |
| Token efficiency | 6.0 | Recoverable bloat. Boilerplate and dead context are billed on every call. |
The seven criteria average to 7.6 out of 10, a grade of adequate. More useful than the headline number is what it points at: guardrail coverage at 5.0 is the single highest-value fix. This is the same agent that, in its behaviour run, approved an out-of-policy refund under social-engineering pressure. The context score explained why before the incident did. The harness prints the breakdown next to the scorecard, with each finding tagged by its token impact so you also see where to cut spend:
Context Engineering 7.6/10 (adequate)
Strong role, tools, and grounding; guardrails are the weak link.
Role Clarity 9.0/10
Guardrail Coverage 5.0/10
Instruction Consistency 8.0/10
Tool Schema Quality 9.0/10
Grounding Sufficiency 9.0/10
Injection Hardening 7.0/10
Token Efficiency 6.0/10
[↑] Missing refusal rules: add explicit refusals for out-of-policy refunds, payments, and PII.
[↓↓] Dead context: drop the deprecated tool catalog and unused persona backstory.
(Separate sub-score, never affects the metric scores or the gate.)
Each finding carries a verdict on its token impact (↓↓ big_cut, ↓ cut, → neutral, ↑ adds) and the run reports an estimate of the tokens you can reclaim, so the same panel answers what is wrong, how to fix it, and where the savings are.
Start Measuring
pip install -U proofagent-harness
# Grade your agent's context as part of a normal run
proof run my_agent.py --assess-context
# Score a finished deliverable and its producing agent's context together
proof artifact ./brd.md --assess-context
# Push the result, including the context engineering sub-score, to the dashboard
proof run my_agent.py --assess-context --upload --agent acme-support --fail-on blockWhen you upload, the context engineering sub-score travels with the report and the dashboard renders it as its own panel, version over version, next to the behaviour scorecard and the compliance posture. Behaviour tells you whether the agent passed. Context engineering tells you whether it was ever set up to.
References
- Liu et al., Lost in the Middle: How Language Models Use Long Contexts (2023).
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020).
- Anthropic, Building Effective Agents (2024), and Anthropic Engineering on effective context engineering for agents (2025).
- Drew Breunig, How Long Contexts Fail and How to Fix Your Context (2025).
- Philipp Schmid, The New Skill in AI Is Context Engineering (2025).
- Simon Willison, writing on prompt injection.
- ProofAgent-Harness: proofagent.ai/harness/docs#context-engineering · PyPI.